*课程框架树# Advanced DSSearchAVL RB B+ [App]Inverted file index heapLeftist Skew Binomial Fibonacci Paring AlgorithmDesign TechniqueBasicGreedy DP Devide and Conquer Backtracking Opti.Approximation Local search miscRandomized *Parallel External Sorting Analysis TechniquePC vs NPC Amortized Analysis Backtracking# 补充定义
S i S_i S i i i i game tree 又叫决策树 例一:八皇后
S i { 1 ⋯ 8 } x i ≠ x j ( i ≠ j ) ∣ ( x i − x j ) ( i − j ) ∣ ≠ 1 ( i ≠ j ) S_i\{1\cdots 8\}\\ x_i\neq x_j(i\neq j)\\ \left|\frac{(x_i-x_j)}{(i-j)}\right|\neq 1(i\neq j) S i { 1 ⋯ 8 } x i = x j ( i = j ) ( i − j ) ( x i − x j ) = 1 ( i = j ) 另外一个例子的阶段 设计则没有那么显然
eg2. Turnpike Reconstruction
S 1 = [ 1 , n ] S i − 1 = S i − { l i } ∨ S i − 1 = S i − { r i } S_1=[1,n] \\S_{i-1} =S_i-\{l_i\}\vee S_{i-1}=S_i-\{r_i\}\\ S 1 = [ 1 , n ] S i − 1 = S i − { l i } ∨ S i − 1 = S i − { r i } 每个阶段的决策并不好用变量来写
具体而言我们考虑用递归的方式定义这个过程
R e c o n s t r u c t i o n ( X , D , N , l , r ) \mathrm{Reconstruction}(X,D,N,l,r) Reconstruction ( X , D , N , l , r )
表示我们已经将[ 1 , l − 1 ] , [ r + 1 , N ] [1,l-1],[r+1,N] [ 1 , l − 1 ] , [ r + 1 , N ] D D D X [ l → r ] X[l\to r] X [ l → r ] 能否 产生可行解的过程
后续递归显然,剪枝即为,我们在选左和选右缩减时需要提前检查是否出现了未知的距离
Alpha-Beta prunning# Minmax Strategy :以tic-tac-toe为例,A与B分别持有最大化/,最小化某一收益的前提目标,则我们可以对game tree奇偶分层分别实现最值Alpha-Beta punning :基于该想法卡上下界(开始进入有奇偶两种),可以在实践中缩减规模到O ( N ) \mathcal O(\sqrt N) O ( N ) N N N Divide and Conquer# Definition# Divide :将问题规模切割成结构相似的子问题Conquer : 递归解决子问题Combine : 总问题的解决依赖子问题的结果,同时也需要合并Closest Points Problem# n n n
算法描述
按照x x x 处理两侧的最近点对和跨点集的最近点对 假设两侧的结果为δ \delta δ [ x 0 − δ , x 0 + δ ] [x_0-\delta,x_0+\delta] [ x 0 − δ , x 0 + δ ] 任意选取范围内一个点,则可更新区域变为[ x 0 − δ , x 0 + δ ] × [ y 0 , y 0 − δ ] [x_0-\delta,x_0+\delta]\times [y_0,y_0-\delta] [ x 0 − δ , x 0 + δ ] × [ y 0 , y 0 − δ ] 可以证明最多只有6个不重合的 点 则复杂度为T ( N ) = 2 T ( N 2 ) + O ( N ) = O ( N log N ) T(N)=2T(\frac{N}{2})+\mathcal O(N)=\mathcal O(N\log N) T ( N ) = 2 T ( 2 N ) + O ( N ) = O ( N log N )
复杂度分析# T ( N ) = a T ( N b ) + f ( N ) , a , b ∈ Z + T(N)=aT(\frac{N}{b})+f(N),a,b\in \mathbb Z^+ T ( N ) = a T ( b N ) + f ( N ) , a , b ∈ Z + 迭代求解法/递归树法# T ( N ) = . . . = c N l e a v e s ⏟ c o n q u e r + ∑ n o d e i n o n − l e a f − n o d e s f ( N n o d e i ) ⏟ c o m b i n e T(N)=...=\underbrace{c N_{leaves}}_{conquer}+\underbrace{\sum_{node_i}^{non-leaf-nodes}f(N_{node_i})}_{combine} T ( N ) = ... = co n q u er c N l e a v es + co mbin e n o d e i ∑ n o n − l e a f − n o d es f ( N n o d e i ) 以T ( N ) = 2 T ( N / 2 ) + O ( N ) T(N)=2T(N/2)+\mathcal O(N) T ( N ) = 2 T ( N /2 ) + O ( N )
T ( N ) = 2 k T ( N 2 k ) + k O ( N ) T(N)=2^kT(\frac{N}{2^k})+k\mathcal O(N) T ( N ) = 2 k T ( 2 k N ) + k O ( N ) k → ∞ , 2 k T ( N 2 k ) → O ( N ) k \to \infty ,2^kT(\frac{N}{2^k})\to \mathcal O(N) k → ∞ , 2 k T ( 2 k N ) → O ( N )
这个基于N 0 ∈ [ 1 , σ ) N_0\in [1,\sigma) N 0 ∈ [ 1 , σ ) T ( N 0 ) = O ( 1 ) T(N_0)=\mathcal O( 1) T ( N 0 ) = O ( 1 )
补充例子
T ( N ) = 3 T ( N 4 ) + Θ ( N 2 ) T(N)=3T(\frac{N}{4})+\Theta (N^2) T ( N ) = 3 T ( 4 N ) + Θ ( N 2 ) 展开有
T ( N ) = ∑ i = 0 log 4 N − 1 ( 3 16 ) i c N 2 + Θ ( N log 4 3 ) < ∑ i = 0 ∞ ( 3 16 ) i c N 2 + Θ ( N log 4 3 ) = c N 2 1 − 3 16 + Θ ( N log 4 3 ) = O ( N 2 ) \begin{align*} T(N)&=\sum _{i=0}^{\log_4N-1}\left(\frac{3}{16}\right)^i cN^2+\Theta (N^{\log _43}) \\&<\sum_{i=0}^\infty \left(\frac{3}{16}\right)^icN^2+\Theta (N^{\log _4 3})\\&=\frac{cN^2}{1-\frac{3}{16}}+\Theta (N^{\log_4 3})=\mathcal O(N^2) \end{align*} T ( N ) = i = 0 ∑ l o g 4 N − 1 ( 16 3 ) i c N 2 + Θ ( N l o g 4 3 ) < i = 0 ∑ ∞ ( 16 3 ) i c N 2 + Θ ( N l o g 4 3 ) = 1 − 16 3 c N 2 + Θ ( N l o g 4 3 ) = O ( N 2 ) 这个过程a = 3 , b = 4 , f ( n ) = Θ ( n 2 ) a=3,b=4,f(n)=\Theta (n^2) a = 3 , b = 4 , f ( n ) = Θ ( n 2 )
代换法/归纳法# 上面这个你猜一下带入即可
T(N) = d N log N − d N ( log 2 3 − 2 3 ) + c N ≤ d N log N f o r d ≥ c / ( log 2 3 − 2 3 ) \begin{gathered} \text{T(N)} \\ =dN\log N-dN(\log_23-\frac23)+cN\leq dN\log N \\ ford\geq c/(\log_23-\frac23) \end{gathered} T(N) = d N log N − d N ( log 2 3 − 3 2 ) + c N ≤ d N log N f or d ≥ c / ( log 2 3 − 3 2 ) Master Method# Form 1
对于形如T ( N ) = a T ( N / b ) + f ( N ) T(N)=aT(N/b)+f(N) T ( N ) = a T ( N / b ) + f ( N ) f ( N ) = O ( N ( log b a ) − ε ) f(N)=O(N^{(\log_ba)-\varepsilon}) f ( N ) = O ( N ( l o g b a ) − ε ) ε > 0 \varepsilon>0 ε > 0 T ( N ) = Θ ( N log b a ) ; T(N)=\Theta(N^{\log_ba}); T ( N ) = Θ ( N l o g b a ) ; f ( N ) = Θ ( N log b a ) f(N)=\Theta(N^{\log_ba}) f ( N ) = Θ ( N l o g b a ) T ( N ) = Θ ( N log b a log N ) ; T(N)=\Theta(N^{\log_ba}\log N); T ( N ) = Θ ( N l o g b a log N ) ; f ( N ) = Ω ( N ( log b a ) + ε ) f(N)=\Omega(N^{(\log_ba)+\varepsilon}) f ( N ) = Ω ( N ( l o g b a ) + ε ) ε > 0 \varepsilon>0 ε > 0 a f ( N b ) < c f ( N ) af(\frac Nb)<cf(N) a f ( b N ) < c f ( N ) c < 1 c<1 c < 1 ∀ N > N 0 \forall N>N_0 ∀ N > N 0 T ( N ) = Θ ( f ( N ) ) T(N)=\Theta(f(N)) T ( N ) = Θ ( f ( N )) regularity condition
注意
Merge sorta = b = 2 a=b=2 a = b = 2 T ( N ) = O ( N log N ) T(N)=\mathcal O(N\log N) T ( N ) = O ( N log N ) a = b = 2 , f ( N ) = N log N a=b=2,f(N)=N\log N a = b = 2 , f ( N ) = N log N f ( N ) = N log N f(N)=N\log N f ( N ) = N log N N log N = Θ ( N l o g 22 ) N\log N=\Theta(N^{log_{2}2}) N log N = Θ ( N l o g 2 2 ) N log N ≠ Θ ( N log 2 2 − ϵ ) N\log N\not=\Theta(N^{\log_2 2−\epsilon}) N log N = Θ ( N l o g 2 2 − ϵ ) 具体来说,lim N → ∞ N log N N 1 + ϵ = lim N → ∞ log N N ϵ = 0 for fixed ϵ > 0 \lim\limits_{N\rightarrow\infty}\frac{N\log N}{N^{1+\epsilon}}=\lim\limits_{N\rightarrow\infty}\frac{\log N}{N^\epsilon}=0\text{ for fixed }\epsilon>0 N → ∞ lim N 1 + ϵ N l o g N = N → ∞ lim N ϵ l o g N = 0 for fixed ϵ > 0 这个例子体现出了 ϵ \epsilon ϵ 对于形如 T ( N ) = a T ( N b ) + f ( N ) T(N)=aT(\frac{N}{b})+f(N) T ( N ) = a T ( b N ) + f ( N )
Case 1
T ( N ) = Θ ( N log b a ) + ∑ j = 0 log b N − 1 a j f ( N b j ) T(N)=\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N-1}a^jf(\frac{N}{b^j}) T ( N ) = Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 a j f ( b j N ) 而我们有条件 f ( N ) = O ( N log b a − ϵ ) , for ϵ > 0 f(N)=O(N^{\log_{b}a−\epsilon}),\text{ for }\epsilon>0 f ( N ) = O ( N l o g b a − ϵ ) , for ϵ > 0
T ( N ) = Θ ( N log b a ) + ∑ j = 0 log b N − 1 a j O ( ( N b j ) log b a − ϵ ) = Θ ( N log b a ) + O ( N log b a − ϵ × ∑ j = 0 log b N − 1 ( a b log b a − ϵ ) j ) = Θ ( N log b a ) + O ( N log b a − ϵ × ∑ j = 0 log b N − 1 ( b ϵ ) j ) = Θ ( N log b a ) + O ( N log b a − ϵ × 1 × ( 1 − ( b ϵ ) log b N ) 1 − b ϵ ) = Θ ( N log b a ) + O ( N log b a − ϵ × N ϵ − 1 b ϵ − 1 ) = Θ ( N log b a ) + O ( N log b a − ϵ × N ϵ ) = Θ ( N log b a ) + O ( N log b a ) = Θ ( N log b a ) \begin{aligned} T(N)&=\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N-1}a^jO((\frac{N}{b^j})^{\log_{b}a-\epsilon})\\ &=\Theta(N^{\log_{b}a})+O(N^{\log_{b}a−\epsilon}×\sum\limits_{j=0}^{\log_{b}N−1}(\frac{a}{b^{\log_{b}a−\epsilon}})^j)\\ &=\Theta(N^{\log_{b}a})+O(N^{\log_{b}a−\epsilon}×\sum\limits_{j=0}^{\log_{b}N−1}(b^\epsilon)^j)\\ &=\Theta(N^{\log_{b}a})+O(N^{\log_{b}a−\epsilon}×\frac{1×(1−(b^\epsilon)^{\log_{b}N})}{1−b^\epsilon})\\ &=\Theta(N^{\log_{b}a})+O(N^{\log_{b}a−\epsilon}×\frac{N^\epsilon-1}{b^\epsilon−1})\\ &=\Theta(N^{\log_{b}a})+O(N^{\log_{b}a−\epsilon}×N^\epsilon)\\ &=\Theta(N^{\log_{b}a})+O(N^{\log_{b}a})\\ &=\Theta(N^{\log_{b}a}) \end{aligned} T ( N ) = Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 a j O (( b j N ) l o g b a − ϵ ) = Θ ( N l o g b a ) + O ( N l o g b a − ϵ × j = 0 ∑ l o g b N − 1 ( b l o g b a − ϵ a ) j ) = Θ ( N l o g b a ) + O ( N l o g b a − ϵ × j = 0 ∑ l o g b N − 1 ( b ϵ ) j ) = Θ ( N l o g b a ) + O ( N l o g b a − ϵ × 1 − b ϵ 1 × ( 1 − ( b ϵ ) l o g b N ) ) = Θ ( N l o g b a ) + O ( N l o g b a − ϵ × b ϵ − 1 N ϵ − 1 ) = Θ ( N l o g b a ) + O ( N l o g b a − ϵ × N ϵ ) = Θ ( N l o g b a ) + O ( N l o g b a ) = Θ ( N l o g b a ) 证毕
Case 2
T ( N ) = Θ ( N log b a ) + ∑ j = 0 log b N − 1 a j f ( N b j ) T(N)=\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N-1}a^jf(\frac{N}{b^j}) T ( N ) = Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 a j f ( b j N ) 而我们有条件 f ( N ) = Θ ( N log b a ) f(N)=\Theta(N^{\log_{b}a}) f ( N ) = Θ ( N l o g b a )
T ( N ) = Θ ( N log b a ) + ∑ j = 0 log b N − 1 a j Θ ( ( N b j ) log b a ) = Θ ( N log b a ) + Θ ( N log b a × ∑ j = 0 log b N − 1 ( a b log b a ) j ) = Θ ( N log b a ) + Θ ( N log b a × log b N ) = Θ ( N log b a log N ) \begin{aligned} T(N)&=\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N−1}a^j\Theta((\frac{N}{b^j})^{\log_{b}a})\\ &=\Theta(N^{\log_{b}a})+\Theta(N^{\log_{b}a}×\sum\limits_{j=0}^{\log_{b}N−1}(\frac{a}{b^{\log_{b}a}})^j)\\ &=\Theta(N^{\log_{b}a})+\Theta(N^{\log_{b}a}×\log_{b}N)\\ &=Θ(N^{\log_{b}a}\logN) \end{aligned} T ( N ) = Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 a j Θ (( b j N ) l o g b a ) = Θ ( N l o g b a ) + Θ ( N l o g b a × j = 0 ∑ l o g b N − 1 ( b l o g b a a ) j ) = Θ ( N l o g b a ) + Θ ( N l o g b a × log b N ) = Θ ( N l o g b a log N ) 证毕
Case 3
T ( N ) = Θ ( N log b a ) + ∑ j = 0 log b N − 1 a j f ( N b j ) T(N)=\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N-1}a^jf(\frac{N}{b^j}) T ( N ) = Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 a j f ( b j N ) 接下来的步骤和之前不同。在继续之前,我们首先观察不等式 a f ( N b ) < c f ( N ) af(\frac{N}{b})<cf(N) a f ( b N ) < c f ( N ) a j f ( N b j ) a^jf(\frac{N}{b^j}) a j f ( b j N )
a j f ( N b j ) < c × a j − 1 f ( N b j − 1 ) < . . . < c j f ( N ) a^jf(\frac{N}{b^j})<c×a^{j−1}f(\frac{N}{b^{j−1}})<...<c^jf(N) a j f ( b j N ) < c × a j − 1 f ( b j − 1 N ) < ... < c j f ( N ) 将这个不等式应用于求和式中,我们能够得到:
T ( N ) < Θ ( N log b a ) + ∑ j = 0 log b N − 1 c j f ( N ) = Θ ( N log b a ) + f ( N ) ∑ j = 0 log b N − 1 c j = Θ ( N log b a ) + f ( N ) × 1 − c log b N 1 − c = Θ ( N log b a ) + f ( N ) × 1 − N log b c 1 − c \begin{aligned} T(N)&<\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N-1}c^jf(N)\\ &=\Theta(N^{\log_{b}a})+f(N)\sum\limits_{j=0}^{\log_{b}N-1}c^j\\ &=\Theta(N^{\log_{b}a})+f(N)\times\frac{1-c^{\log_{b}N}}{1-c}\\ &=\Theta(N^{\log_{b}a})+f(N)\times\frac{1-N^{\log_{b}c}}{1-c} \end{aligned} T ( N ) < Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 c j f ( N ) = Θ ( N l o g b a ) + f ( N ) j = 0 ∑ l o g b N − 1 c j = Θ ( N l o g b a ) + f ( N ) × 1 − c 1 − c l o g b N = Θ ( N l o g b a ) + f ( N ) × 1 − c 1 − N l o g b c 而由于 c < 1 c<1 c < 1 log b c < 0 \log_{b}c<0 log b c < 0 N > 0 N>0 N > 0 N log b c ∈ ( 0 , 1 ) N\log_{b}c\in(0,1) N log b c ∈ ( 0 , 1 ) c c c 1 − N log b c 1 − c ∈ ( 0 , 1 1 − c ) \frac{1−N^{\log_{b}c}}{1−c}\in(0,\frac{1}{1−c}) 1 − c 1 − N l o g b c ∈ ( 0 , 1 − c 1 )
因此,上式便能改变为:
T ( N ) < Θ ( N log b a ) + f ( N ) × 1 − N log b c 1 − c < Θ ( N log b a ) + f ( N ) × 1 1 − c \begin{aligned} T(N)&<\Theta(N^{\log_{b}a})+f(N)\times\frac{1-N^{\log_{b}c}}{1-c}\\ &<\Theta(N^{\log_{b}a})+f(N)\times\frac{1}{1-c} \end{aligned} T ( N ) < Θ ( N l o g b a ) + f ( N ) × 1 − c 1 − N l o g b c < Θ ( N l o g b a ) + f ( N ) × 1 − c 1 并且,由于 f ( N ) = Ω ( N log b a + ϵ ) , for ϵ > 0 f(N)=\Omega(N^{\log_{b}a+\epsilon}),\text{ for }\epsilon>0 f ( N ) = Ω ( N l o g b a + ϵ ) , for ϵ > 0 c 2 N log b a + ϵ < f ( N ) ⇒ N log b a < 1 c 2 N ϵ f ( N ) c_2N^{\log_{b}a+\epsilon}<f(N)\Rightarrow N^{\log_{b}a}<\frac{1}{c_2N^\epsilon}f(N) c 2 N l o g b a + ϵ < f ( N ) ⇒ N l o g b a < c 2 N ϵ 1 f ( N ) T ( N ) < Θ ( N log b a ) + f ( N ) × 1 1 − c < c 1 N log b a + f ( N ) × 1 1 − c < ( c 1 c 2 N ϵ + 1 1 − c ) f ( N ) = O ( f ( N ) ) T(N)<\Theta(N^{\log_{b}a})+f(N)\times\frac{1}{1-c}<c_1N^{\log_{b}a}+f(N)\times\frac{1}{1-c}<(\frac{c_1}{c_2N^\epsilon}+\frac{1}{1-c})f(N)=O(f(N)) T ( N ) < Θ ( N l o g b a ) + f ( N ) × 1 − c 1 < c 1 N l o g b a + f ( N ) × 1 − c 1 < ( c 2 N ϵ c 1 + 1 − c 1 ) f ( N ) = O ( f ( N ))
而我们知道,要证明 T ( N ) = Θ ( f ( N ) ) T(N)=\Theta(f(N)) T ( N ) = Θ ( f ( N )) T ( N ) = Ω ( f ( N ) ) T(N)=\Omega(f(N)) T ( N ) = Ω ( f ( N ))
T ( N ) = Θ ( N log b a ) + ∑ j = 0 log b N − 1 a j f ( N b j ) ≥ ∑ j = 0 log b N − 1 a j f ( N b j ) ≥ f ( N ) T(N)=Θ(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N−1}a^jf(\frac{N}{b^j}) \geq\sum\limits_{j=0}^{\log_{b}N−1}a^jf(\frac{N}{b^j})\geq f(N) T ( N ) = Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 a j f ( b j N ) ≥ j = 0 ∑ l o g b N − 1 a j f ( b j N ) ≥ f ( N ) 由此得到 T ( N ) = Ω ( f ( N ) ) T(N)=\Omega(f(N)) T ( N ) = Ω ( f ( N )) T ( N ) = Θ ( f ( N ) ) T(N)=\Theta(f(N)) T ( N ) = Θ ( f ( N ))
Form 2
对于形如 T ( N ) = a T ( N b ) + f ( N ) T(N)=aT(\frac{N}{b})+f(N) T ( N ) = a T ( b N ) + f ( N )
若 a f ( N b ) = κ f ( N ) for fixed κ < 1 af(\frac{N}{b})=\kappa f(N)\text{ for fixed }\kappa <1 a f ( b N ) = κ f ( N ) for fixed κ < 1 T ( N ) = Θ ( f ( N ) ) T(N)=\Theta(f(N)) T ( N ) = Θ ( f ( N )) 若 a f ( N b ) = κ f ( N ) for fixed κ > 1 af(\frac{N}{b})=\kappa f(N)\text{ for fixed }\kappa >1 a f ( b N ) = κ f ( N ) for fixed κ > 1 T ( N ) = Θ ( N log b a ) = Θ ( a log b N ) T(N)=\Theta(N^{\log_{b}a})=\Theta(a^{\log_{b}N}) T ( N ) = Θ ( N l o g b a ) = Θ ( a l o g b N ) 若 a f ( N b ) = f ( N ) af(\frac{N}{b})=f(N) a f ( b N ) = f ( N ) T ( N ) = Θ ( f ( N ) l o g b N ) T(N)=\Theta(f(N)log_{b}N) T ( N ) = Θ ( f ( N ) l o g b N ) 对于形如 T ( N ) = a T ( N b ) + f ( N ) T(N)=aT(\frac{N}{b})+f(N) T ( N ) = a T ( b N ) + f ( N )
假设我们有 a f ( N b ) = c f ( N ) af(\frac{N}{b})=cf(N) a f ( b N ) = c f ( N )
类似于形式一的第三种情况的证明,我们迭代该关系式,得到关系:
a j f ( N b j ) = c j f ( N ) a^jf(\frac{N}{b^j})=c^jf(N) a j f ( b j N ) = c j f ( N ) 于是,我们有:
T ( N ) < Θ ( N log b a ) + ∑ j = 0 log b N − 1 c j f ( N ) = Θ ( N log b a ) + f ( N ) ∑ j = 0 log b N − 1 c j = Θ ( N log b a ) + f ( N ) × 1 − c log b N 1 − c = Θ ( N log b a ) + f ( N ) × 1 − N log b c 1 − c \begin{aligned} T(N)&<\Theta(N^{\log_{b}a})+\sum\limits_{j=0}^{\log_{b}N-1}c^jf(N)\\ &=\Theta(N^{\log_{b}a})+f(N)\sum\limits_{j=0}^{\log_{b}N-1}c^j\\ &=\Theta(N^{\log_{b}a})+f(N)\times\frac{1-c^{\log_{b}N}}{1-c}\\ &=\Theta(N^{\log_{b}a})+f(N)\times\frac{1-N^{\log_{b}c}}{1-c} \end{aligned} T ( N ) < Θ ( N l o g b a ) + j = 0 ∑ l o g b N − 1 c j f ( N ) = Θ ( N l o g b a ) + f ( N ) j = 0 ∑ l o g b N − 1 c j = Θ ( N l o g b a ) + f ( N ) × 1 − c 1 − c l o g b N = Θ ( N l o g b a ) + f ( N ) × 1 − c 1 − N l o g b c 我们现在并不像 Form 1 有显式的 f ( N ) = Ω ( N log b a + ϵ ) f(N)=\Omega(N^{\log_{b}a+\epsilon}) f ( N ) = Ω ( N l o g b a + ϵ ) f ( N ) = Ω ( N log b a ) f(N) = \Omega(N^{\log_{b}a}) f ( N ) = Ω ( N l o g b a ) a f ( N b ) ∼ c f ( N ) af(\frac{N}{b})∼cf(N) a f ( b N ) ∼ c f ( N ) N log b a N^{\log_{b}a} N l o g b a
c f ( N ) ∼ a f ( N b ) ∼ . . . ∼ a L f ( N b L ) cf(N)∼af(\frac{N}{b})∼...∼a^Lf(\frac{N}{b^L}) c f ( N ) ∼ a f ( b N ) ∼ ... ∼ a L f ( b L N ) 可以发现,这一步还是和 Form 1 的第三种情况的证明过程高度相似。只不过现在我们要更进一步地看这个式子。
当 c < 1 c<1 c < 1 f ( N ) > a f ( N b ) f(N)>af(\frac{N}{b}) f ( N ) > a f ( b N ) c = 1 c=1 c = 1 f ( N ) = a f ( N b ) f(N)=af(\frac{N}{b}) f ( N ) = a f ( b N ) c > 1 c>1 c > 1 f ( N ) < a f ( N b ) f(N)<af(\frac{N}{b}) f ( N ) < a f ( b N )
我们假设 N b L \frac{N}{b^L} b L N N b L = Θ ( 1 ) \frac{N}{b^L}=\Theta(1) b L N = Θ ( 1 ) L = Θ ( log b N ) L=\Theta(\log_{b}N) L = Θ ( log b N )
f ( N ) ∼ Θ ( a log b N ) = Θ ( N log b a ) f(N)∼Θ(a^{\log_{b}N})=Θ(N^{\log_{b}a}) f ( N ) ∼ Θ ( a l o g b N ) = Θ ( N l o g b a ) 剩下的证明就跟 Form 1 的第三种情况一致
Form 3
当递推关系满足:
T ( N ) = a T ( N b ) + Θ ( N k log p N ) Where a ≥ 1 , b > 1 , p ≥ 0 T(N)=aT(\frac{N}{b})+\Theta(N^k\log^{p}N)\text{ Where }a\geq 1,b>1,p\geq 0 T ( N ) = a T ( b N ) + Θ ( N k log p N ) Where a ≥ 1 , b > 1 , p ≥ 0 其复杂度有结论:
T ( N ) = { O ( N log b a ) , a > b k O ( N k log p + 1 N ) , a = b k O ( N k log p N ) , a < b k T(N)= \begin{cases} O(N^{\log_{b}a}),a>b^k\\ O(N^k\log^{p+1}N),a=b^k\\ O(N^k\log^{p}N),a<b^k \end{cases} T ( N ) = ⎩ ⎨ ⎧ O ( N l o g b a ) , a > b k O ( N k log p + 1 N ) , a = b k O ( N k log p N ) , a < b k (Chap4.5 4.1Master Method)
Form4
对于形如T ( N ) = a T ( N / b ) + f ( N ) T(N)=aT(N/b)+f(N) T ( N ) = a T ( N / b ) + f ( N ) f ( N ) = O ( N ( log b a ) − ε ) f(N)=O(N^{(\log_ba)-\varepsilon}) f ( N ) = O ( N ( l o g b a ) − ε ) ε > 0 \varepsilon>0 ε > 0 T ( N ) = Θ ( N log b a ) ; T(N)=\Theta(N^{\log_ba}); T ( N ) = Θ ( N l o g b a ) ; f ( N ) = Θ ( N log b a log k N ) f(N)=\Theta(N^{\log_ba}\log^k N) f ( N ) = Θ ( N l o g b a log k N ) T ( N ) = Θ ( N log b a log k + 1 N ) ; T(N)=\Theta(N^{\log_ba}\log^{k+1} N); T ( N ) = Θ ( N l o g b a log k + 1 N ) ; f ( N ) = Ω ( N ( log b a ) + ε ) f(N)=\Omega(N^{(\log_ba)+\varepsilon}) f ( N ) = Ω ( N ( l o g b a ) + ε ) ε > 0 \varepsilon>0 ε > 0 a f ( N b ) < c f ( N ) af(\frac Nb)<cf(N) a f ( b N ) < c f ( N ) c < 1 c<1 c < 1 ∀ N > N 0 \forall N>N_0 ∀ N > N 0 T ( N ) = Θ ( f ( N ) ) T(N)=\Theta(f(N)) T ( N ) = Θ ( f ( N )) regularity condition
实际上就是Form3的重述
Dynamic Programming# Principle# 处理最优化问题,要求具有最优子结构。
Ordering Matrix Multiplications【Interval DP】# 题即其意
m i , j = min i ⩽ l < j { m i , l + m l + 1 , j + r i − 1 r l r j } m_{i,j}=\min_{i\leqslant l<j}\{m_{i,l}+m_{l+1,j}+r_{i-1}r_lr_j\} m i , j = i ⩽ l < j min { m i , l + m l + 1 , j + r i − 1 r l r j } 这里关于连乘方案,实际上就是画括号(卡特兰数)
b n = ∑ i < n b i b n − i − 1 b_n=\sum _{i<n}b_ib_{n-i-1} b n = i < n ∑ b i b n − i − 1 b n = ( 2 n n ) n + 1 = O ( 4 n n 3 2 ) b_n=\frac{\binom{2n}{n}}{n+1}=\mathcal O(\frac{4^n}{n^{\frac{3}{2}}}) b n = n + 1 ( n 2 n ) = O ( n 2 3 4 n )
Optimal Binary Search Tree【Interval DP】# 给定一些words 有w 1 < w 2 < ⋯ w n w_1<w_2<\cdots w_n w 1 < w 2 < ⋯ w n p i p_i p i w w w
T ( n ) = ∑ i = 1 n p i ( 1 + d i ) T(n)=\sum_{i=1}^n p_i(1+d_i) T ( n ) = i = 1 ∑ n p i ( 1 + d i ) 假设T i , j \mathcal T_{i,j} T i , j [ i , j ] [i,j] [ i , j ]
c i , j c_{i,j} c i , j r i , j r_{i,j} r i , j w i , j w_{i,j} w i , j ∑ k = i j p k \sum _{k=i}^j p_k ∑ k = i j p k
c i , j = c i , k − 1 + c k + 1 , j + w i , j c_{i,j}=c_{i,k-1}+c_{k+1,j}+w_{i,j} c i , j = c i , k − 1 + c k + 1 , j + w i , j 这里相当于是考虑从哪里分开
Floyd# 设f k ( i , j ) f_k(i,j) f k ( i , j ) i → [ l ⩽ k ] → j i\to [l\leqslant k]\to j i → [ l ⩽ k ] → j
f k ( i , j ) = min { f k − 1 ( i , j ) , f k − 1 ( i , k ) + f k − 1 ( k , j ) } f_{k}(i,j)=\min \{f_{k-1}(i,j),f_{k-1}(i,k)+f_{k-1}(k,j)\} f k ( i , j ) = min { f k − 1 ( i , j ) , f k − 1 ( i , k ) + f k − 1 ( k , j )}
注意到我们不需要存k k k
Greedy Algorithm# Greedy Principle# 整体上
Huffman tree/code# Np Completness# 这是一个
Concept# 图灵机
多项式归约≤ P \leq_P ≤ P A ≤ P B ⇔ ∃ f A\leq_P B \Leftrightarrow \exist f A ≤ P B ⇔ ∃ f f ( A ) = B , f − 1 ( B ) = A f(A)=B,f^{-1}(B)=A f ( A ) = B , f − 1 ( B ) = A
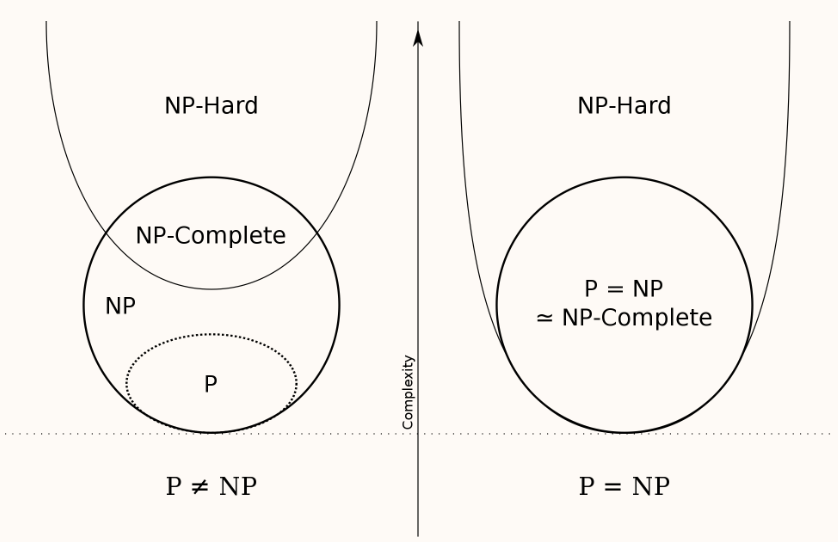
P(Polynomial Time)
NP(Nondeterministic Polynomial Time)
NPC
是NP
B ∈ N P , ∀ A ∈ N P , A ≤ P B ⇒ B ∈ N P C B\in NP,\forall A\in NP,A\leq _P B\Rightarrow B\in NPC B ∈ NP , ∀ A ∈ NP , A ≤ P B ⇒ B ∈ NPC B ∈ N P , A ∈ N P C , A ≤ P B → B ∈ N P C B\in NP,A\in NPC,A\leq _P B\to B \in NPC B ∈ NP , A ∈ NPC , A ≤ P B → B ∈ NPC NPH(NP Hard)
Undecidable 不可判定
NPC# 第一个是Circuit-SAT->3-SAT
3SAT约束了布尔表达式的范式
( x 1 ∨ x 2 ∨ x 3 ) ∧ ( x 4 ) (x1\vee x2\vee x3)\wedge (x_4) ( x 1 ∨ x 2 ∨ x 3 ) ∧ ( x 4 ) NPH# 经典问题#
Approximation# Approximation Ratio & Scheme# ρ = max { f n ( x ) f n ( x ∗ ) , f n ( x ∗ ) f n ( x ) } \rho =\max \left\{\frac{f_n(x)}{f_n(x^*)},\frac{f_n(x^*)}{f_n(x)}\right\} ρ = max { f n ( x ∗ ) f n ( x ) , f n ( x ) f n ( x ∗ ) }
则称算法为 ρ \rho ρ
近似范式是对一个优化问题,一族相同模式的算法
满足ρ ⩽ 1 + ε , ε > 0 \rho\leqslant 1+\varepsilon,\varepsilon >0 ρ ⩽ 1 + ε , ε > 0
复杂度可以记为
称为完全多项式时间近似范式**(Fully Polynomial-Time Approximation Scheme, FPTAS)**
在PTAS中,ε \varepsilon ε
Examples# Bin Packing# n个a i ∈ ( 0 , 1 ] a_i\in(0,1] a i ∈ ( 0 , 1 ] ⩽ 1 \leqslant 1 ⩽ 1
变种 k k k n n n a i a_i a i
Online Algorithm# NF Next Fit# NF策略总是选择最后一个组加
ρ = sup A I G ( I ) O P T ( I ) \rho=\sup \frac{AIG(I)}{OPT(I)} ρ = sup OPT ( I ) A I G ( I ) O P T ⩾ 总和 ⩾ ⌈ N F / 2 ⌉ \mathrm{OPT}\geqslant 总和\geqslant \lceil NF/2\rceil OPT ⩾ 总和 ⩾ ⌈ NF /2 ⌉ 这里我们当然可以详细写,没必要
这里有一种构造让其取到2
如何让近似比更小?
First/Best Fit# 总是找第一个/最紧的bin
有1.7的界
最适合的垃圾箱包装 - 维基百科 --- Best-fit bin packing - Wikipedia
All in all# 具体来说,有以下定理:对于本题的所有近似算法,得到的近似解桶数至少是最优解桶数 5 3 \frac{5}{3} 3 5 离线算法 来提升近似的准确度。
对手法
证明演示
我们作为对手和对面达成公式,你不能
我们首先构造34 34 34
则此时你不能开
因为你开了就产生了ρ ⩾ 2 \rho \geqslant 2 ρ ⩾ 2
然后接着给你两个17
Offline# FFD# 降序然后BF,
⩽ 11 9 M + 6 9 \leqslant \frac{11}{9}M+\frac{6}{9} ⩽ 9 11 M + 9 6
Knapsack# Greedy PTAS# 结合起来
A I G ⩾ max { x , y } , O P T = x + y AIG\geqslant \max\{x,y\},OPT=x+y A I G ⩾ max { x , y } , OPT = x + y
我们可以设计
y ⩽ ε O P T y\leqslant \varepsilon OPT y ⩽ εOPT
这里你可以取1 / ε 1/\varepsilon 1/ ε
DP FPTAS# 很容易写一个
O ( n 2 p m a x ) \mathcal O(n^2 p_{max}) O ( n 2 p ma x ) 但是注意,我们是关于
n , log p m a x n,\log p_{max} n , log p ma x 的多项式
这里有一种Round about的技术
p i ′ → ⌊ p i α ⌋ α = ε p m a x n → p i ′ ⩽ n ε p'_i\to \lfloor\frac{p_i}{\alpha }\rfloor\\\alpha =\frac{\varepsilon p_{max}}{n}\to p'_i\leqslant \frac{n}{\varepsilon} p i ′ → ⌊ α p i ⌋ α = n ε p ma x → p i ′ ⩽ ε n ( 1 + ϵ ) P a l g ⩾ P (1+\epsilon )P_{alg}\geqslant P ( 1 + ϵ ) P a l g ⩾ P K-center# 给一堆点,找K个,求最小K圆覆盖半径
注意这里距离是基于度量空间的
设C = { c 1 , c 2 , ⋯ , c k } C=\{c_1,c_2,\cdots,c_k\} C = { c 1 , c 2 , ⋯ , c k } k k k S = { s 1 , ⋯ , s n } S=\{s_1,\cdots,s_n\} S = { s 1 , ⋯ , s n } n n n
minimize r ( C ) = max s i ∈ S { min c i ⩽ C { dis ( s i , c i ) } } \text{minimize~} r(C) =\max _{s_i\in S}\{\min _{c_i\leqslant C} \{\text{dis}(s_i,c_i) \}\} minimize r ( C ) = max s i ∈ S { min c i ⩽ C { dis ( s i , c i )}}
Naive Greedy# 每次选能让下降最多的
Smarter# 说这个近似比是2
Themory:不可近似性# K-center问题有没有ρ < 2 \rho<2 ρ < 2 P = N P P=NP P = NP
本质是找一个NPC,用一个ρ < 2 \rho<2 ρ < 2
具体而言是支配集
选定一个最小的子集,使得剩余点和这个子集中至少一个点相连
这是一个NPC问题
假设我们存在一个ρ < 2 \rho <2 ρ < 2 A l G AlG A lG G ′ G' G ′
我们对于G ( V , E ) G(V,E) G ( V , E )
构造d i s ( v , u ) = { 0 u = v 1 u → v 2 u ↛ v \mathrm{dis}(v,u)=\begin{cases}0&u=v\\1&u\to v\\ 2&u\not \to v \end{cases} dis ( v , u ) = ⎩ ⎨ ⎧ 0 1 2 u = v u → v u → v
r ( C ) ∈ { 1 , 2 } r(C)\in\{1,2\} r ( C ) ∈ { 1 , 2 } r(C)=1已经找到。r ( C ) > 1 → r ( C ∗ ) > 1 r(C)>1\to r(C^*)>1 r ( C ) > 1 → r ( C ∗ ) > 1
这里具体的定义给了很多约束
这里可以换距离定义
Local Search# 整体刻画# L ( S ) \mathcal L(S) L ( S ) S S S argmax L ( S ) \operatorname{argmax}\mathcal L(S) argmax L ( S ) S → S ′ S\to S' S → S ′ 符合要求 的邻集👀 F S → ∙ , F S → small \mathcal {FS}\to \bullet,\mathcal {FS}\xrightarrow{\text{small~}} F S → ∙ , F S small GD - Climbing Algorithm# 这里实际上是假的梯度下降,每次我们选择邻集中的最值走
S ′ → argmax N ( S ) S'\to \operatorname{argmax} N(S) S ′ → argmax N ( S ) Vertex Cover Problem
这里我们构造L ( S ) → ∣ S ∣ \mathcal L (S)\to |S| L ( S ) → ∣ S ∣
容易发现类似菊花图,线,完全二分图这种,假设你有一步没有删除对,则一定会导致不对
The Metropolis Algorithm# 我们随机选取邻集,假设更优就接受,假设不优
依赖e − Δ L k T e^{-\frac{\Delta \mathcal L }{kT}} e − k T Δ L
IMPORTANT Simulated Annealing
我们构造温度衰减
由于这里我们可能接受坏 的结果,因此我们
Hopfield Neural Networks# 给图定黑白色,找有无方案使得 ∀ u ∈ S , ∑ ( u , v ) ∈ E w e s u s v ⩽ 0 \forall u\in S,\displaystyle \sum _{(u,v)\in E}w_es_us_v\leqslant 0 ∀ u ∈ S , ( u , v ) ∈ E ∑ w e s u s v ⩽ 0
State-flipping Algorithm: 可以证明T ⩽ ∑ e ∣ w e ∣ \mathcal T\leqslant \sum _{e}|w_e| T ⩽ ∑ e ∣ w e ∣
Proof
Φ ( S ) = ∑ e , s u ≠ s v ∣ w e ∣ \Phi (S)=\sum _{e,s_u\neq s_v} |w_e| Φ ( S ) = e , s u = s v ∑ ∣ w e ∣ 有
Φ ( S ′ ) = Φ ( S ) − ∑ e u i s b a d ∣ w e ∣ + ∑ e u i s g o o d ∣ w e ∣ ⩾ Φ ( S ) \Phi(S')=\Phi(S)-\sum _{e_u\mathtt {~is~bad}}|w_e|+\sum _{e_u\mathtt {~is~good}}|w_e|\geqslant \Phi(S) Φ ( S ′ ) = Φ ( S ) − e u is bad ∑ ∣ w e ∣ + e u is good ∑ ∣ w e ∣ ⩾ Φ ( S ) 有0 ⩽ Φ ( S ) ⩽ W 0\leqslant \Phi(S)\leqslant W 0 ⩽ Φ ( S ) ⩽ W
目标变成最大Φ \Phi Φ
直接做肯定不是多项式的
The Maximum Cut Problem # 给图定黑白色,最大化∑ u ∈ A , v ∈ B w u v \displaystyle \sum _{u\in A,v\in B}w_{uv} u ∈ A , v ∈ B ∑ w uv
本质上是上一题w ⩾ 0 w\geqslant 0 w ⩾ 0
这里我们需要证明局部最优解有2 2 2
设最优解为w ( A ∗ , B ∗ ) w(A^*,B^*) w ( A ∗ , B ∗ )